












par Benjamin Lallement, conseiller DevOps et membre du collectif Gologic.
Objectifs de cette série
Cette série d’articles a pour but d’explorer les différents outils pour effectuer des déploiements en pipeline as code.
L’objectif pour chaque article reste le même : récupérer le code source depuis GIT, compiler un projet JAVA/Spring-Boot avec Maven, lancer les tests puis déployer l’application sur AWS BeanStalk.
Ces étapes seront écrites sous forme de code dans un pipeline et exécutées avec un outil CI/CD.
Chaque article sera divisé en plusieurs parties :
- Installation et démarrage d’un outil CI/CD
- Configuration de l’outil CI/CD (si nécessaire)
- Développement du pipeline de déploiement continu
- Vérification du déploiement
- Conclusion simple
Si vous voulez exécuter un pipeline, vous aurez besoin de :
- Runtime Docker pour exécuter les étapes du pipeline.
- Un environnement AWS BeanStalk avec clé d’accès et secret pour déployer l’application.
Avant de commencer, définissons deux concepts clés : déploiement continu et pipeline as code.
Que signifie “déploiement continu”?
Le déploiement continu est étroitement lié à l’intégration continue et fait référence à la mise en production d’un logiciel qui réussit les tests automatisés.
“Essentially, it is the practice of releasing every good build to users”, explique Jez Humble, auteur du livre Continuous Delivery.
En adoptant à la fois l’intégration continue et le déploiement continu, vous réduisez non seulement les risques et les erreurs rapidement, mais vous améliorer régulièrement les applications pour arriver à une meilleure solution.
Avec des livraisons plus rapides et régulières, vous pouvez rapidement vous adapter aux besoins de l’entreprise et aux besoins des utilisateurs. Cela permet une plus grande collaboration entre les opérations et la livraison, ce qui transforme votre processus de livraison en un avantage commercial.
Que signifie “pipeline as code”?
Les équipes font pression pour automatiser leurs environnements (tests), y compris l’infrastructure.
Le “pipeline as code” permet de définir les étapes de déploiement via du code au lieu de configurer ces étapes manuellement.
Code source
La référence de la démo est disponible dans GitHub : Continuous Deployment Demo
Jenkins
Objectif
Pour ce premier article, Jenkins sera le cobaye.
Jenkins est un serveur d’automatisation opensource écrit en Java. Jenkins aide à automatiser la partie manuelle du processus de développement, avec une intégration continue. Il facilite également les aspects techniques de la livraison continue. Il s’agit d’un système basé sur un serveur qui s’exécute dans des conteneurs de servlets tels qu’Apache Tomcat. Les tâches peuvent être déclenchées par différents moyens comme par exemple en vérifiant les commits dans GIT, en les déclenchant par “cron”. Il peut également être déclenché une fois que les autres builds de la file d’attente sont terminés. Les fonctionnalités de Jenkins peuvent être étendues avec des plugins.
Installer et exécuter Jenkins avec Docker
Exécuter Jenkins docker container
Exécutez la commande docker suivante pour exécuter Jenkins :
docker run -p 8080:8080 -p 50000:50000 jenkins/jenkins:lts
Plus de détails sur wiki.jenkins.io
Puis connectez-vous à Jenkins à l’adresse http://localhost:8080 en utilisant le mot de passe généré dans les journaux de démarrage de Jenkins.
ex:
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
f421195b70e74f718bd2cc2377debf51
Installer les derniers plugins
Première installation, Jenkins propose d’installer une série de plugins suggérés. Let’s do it!
Créer un premier utilisateur
Ready to rock!
Configuration de la sécurité
Pour pouvoir télécharger le code source du projet et le déployer vers AWS, Jenkins doit accéder aux informations d’identification. Jenkins a sa propre “voute” pour stocker les informations d’identification.
Accédez à http://localhost:8080/credentials/store/system/domain/_/newCredentials
-
- Créer les configurations d’identification GIT pour accéder à votre référentiel (nom d’utilisateur/mot de passe ou clé SSH)
- Créez les configurations d’identification du nom d’utilisateur/mot de passe AWS (id: AWS) pour vous connecter à votre compte AWS (
AWS_ACCESS_KEY_IDetAWS_SECRET_ACCESS_KEY). Plus de détails sur Documentation AWS .
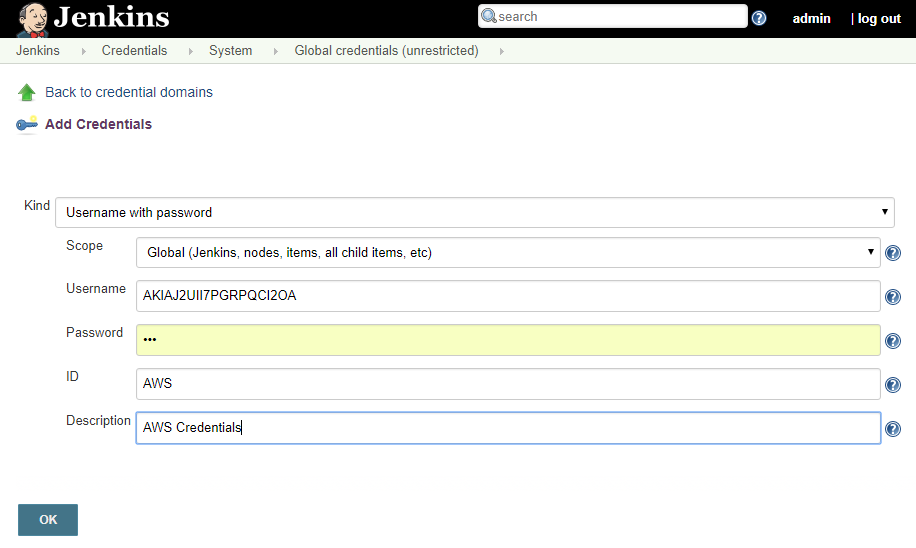
La “voute” de Jenkins possède une arborescence pour gérer la sécurité à plusieurs niveaux. Dans cet article, les informations d’identification sont ajoutées en tant qu’identification globale afin que tous les builds puissent les utiliser rapidement.
Créer le premier Job Jenkins Pipeline
Commencons par créer le premier pipeline.
Dans l’onglet “pipeline” :
- Définition : script de pipeline de SCM
- SCM : GIT
- URL du référentiel : [votre référentiel git]
- Informations d’identification : [Informations d’identification GIT]
- Laissez les autres paramètres par défaut (branche : master, chemin du script : Jenkinsfile)
- Ensuite, il reste à enregistrer et configurer le pipeline dans les sources du projet.

Pipeline as code : let’s get started
Dans les sources du projet, ouvrez le script Jenkinsfile et étudiez le contenu :
node {
// 1. Pipeline options: check for code change in GIT' and keep only two days of history.
properties([pipelineTriggers([pollSCM('5 * * * *')]),[$class: 'BuildDiscarderProperty', strategy: [$class: 'LogRotator', daysToKeepStr: '2', numToKeepStr: '5']]]);
// 2. Clean workspace and checkout code from job SCM configurations
stage("Checkout") {
deleteDir()
checkout scm
}
// 3. Let's build application within a Maven docker image
stage("Build") {
// Compile, Test and Package
docker.image('maven').inside {
sh "mvn package"
}
}
// 4. Add Job Junit reporting inside Jenkins
stage("Report tests") {
junit allowEmptyResults: true, testResults: '**/TEST-*.xml'
}
// 5. Deploy to AWS using Security credentials: ACCESS_KEY and SECRET from custom IAM Jenkins user
docker.image('chriscamicas/awscli-awsebcli').inside {
withCredentials([[$class: 'UsernamePasswordMultiBinding', credentialsId: 'AWS', usernameVariable: 'AWS_ACCESS_KEY_ID', passwordVariable: 'AWS_SECRET_ACCESS_KEY']]) {
// Prepare environment by creating and prepare environments
stage('Prepare environment') {
sh 'eb init continuous-deployment-demo -p "64bit Amazon Linux 2017.09 v2.6.4 running Java 8" --region "ca-central-1" '
// Since AWS failed on create if environment already exists, try/catch block allow to continue deploy without failing
try {
sh 'eb create jenkins-env --single'
} catch(e) {
echo "Error while creating environment, continue..., cause: " + e
}
sh 'eb use jenkins-env'
sh 'eb setenv SERVER_PORT=5000'
}
// Ready to deploy our new version !
stage('Deploy') {
sh 'eb deploy'
sh 'eb status'
}
}
}
}
Pour exécuter ce Pipeline, soit retournez dans Jenkins et cliquez sur “Build Now” dans la tâche, soit faites un changement dans le code source et attendez 5 minutes!
Le script de pipeline (Jenkinsfile) est dans l’application. Il évolue au rythme de l’application et réside au même niveau que les sources.
Chaque changement déclenche une nouvelle exécution de cette tâche et redéploiera sur AWS la nouvelle version!
Conclusion
![]() Jenkins possède une tonne de plugins pour orchestrer de multiples outils et plateformes.
Jenkins possède une tonne de plugins pour orchestrer de multiples outils et plateformes.
![]() Jenkins possède un système de “voute”, de stockage, de configuration. Jenkins fonctionne comme un système autonome.
Jenkins possède un système de “voute”, de stockage, de configuration. Jenkins fonctionne comme un système autonome.
![]() Jenkins pipeline as code (Jenkinsfile) permet de partager du code par une mécanique de librairie partagée, pratique pour des opérations communes.
Jenkins pipeline as code (Jenkinsfile) permet de partager du code par une mécanique de librairie partagée, pratique pour des opérations communes.
![]() Jenkins-cli est peu avancé par rapport aux autres outils CI/CD, alors l’interface Web est requise dans la plupart des cas.
Jenkins-cli est peu avancé par rapport aux autres outils CI/CD, alors l’interface Web est requise dans la plupart des cas.
![]() Jenkins pipeline as code (Jenkinsfile) est basé sur le langage Groovy mais contient une syntaxe spécifique nécessitant un apprentissage.
Jenkins pipeline as code (Jenkinsfile) est basé sur le langage Groovy mais contient une syntaxe spécifique nécessitant un apprentissage.


